
Не секрет, что хорошо настроенный сервер "падает" гораздо реже, чем доступ из него в Интернет.
Всё дело в том, что современная сеть Интернет устроена по принципу автономных систем (AS) и не гарантирует (а никто изначально и не собирался) доступность всех пользователей из всех точек. В Интернет есть понятие соседей - тех провайдеров, через кого ходит ваш трафик, но каждый здесь сам за себя: кто упал, тот чинится. Бывает, что падают мелкие провайдеры, падают крупные - это почти живая экосистема, где доступность - решение задачки на графы (а на практике настройки BGP, который решает эту задачку).
Мониторя серверы, нам в первую очередь важно понять, что явилось причиной простоя и как это чинить прямо сейчас. Хороший мониторинг позволяет одним взглядом на дашборд увидеть: базы, сервисы, хранилища, nginx, ... - живы и не перегружены, а вот доступа в интернет нету. Либо наоборот, что живо все, кроме балансировщика, а резервирование ждет свои 20 секунд. Так как же это увидеть без доступа к серверу? Обычно без доступа можно увидеть только ошибку подключения к zabbix-agent, nrpe, snmp... Мы решили задачу элементарно: своя простая сетка для нужд сборки метрик, бекапа и обслуживания, исключающая самую неконтролируемую нами среду - Интернет.
Так как наши клиенты с наиболее жестким SLA раскиданы по разным ЦОДам города Москвы, то пришлось построить распределенное кольцо из трех маршрутизаторов. Оно и стало ядром сети.
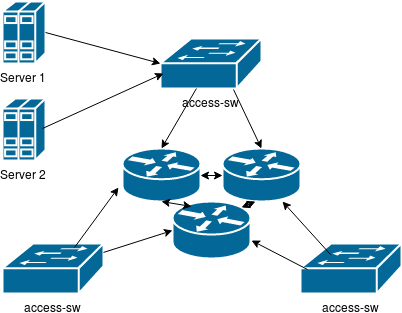 К ядру подключены коммутаторы, размещенные в тех же ЦОД, что и клиенты, к коммутаторам вторые/третьи интерфейсы серверов и IPMI/iDRAC для аварийного управления (дай бог, чтобы и далее оно было нужно только для подстраховки планового обновления ядра ОС).
К ядру подключены коммутаторы, размещенные в тех же ЦОД, что и клиенты, к коммутаторам вторые/третьи интерфейсы серверов и IPMI/iDRAC для аварийного управления (дай бог, чтобы и далее оно было нужно только для подстраховки планового обновления ядра ОС).
В итоге выполнять бекапы по свободному гигабиту быстро, мониторинг отделяет мух от котлет и выдает четкую диагностику, клиенты имеют "локалку в подарок", а IPMI/iDRAC и прочее интимное не торчит в Интернет.
Сеть вышла и правда очень простой: она не требует высоких пропускных способностей в десятки гигабит, не требует какой-то хитрой маршрутизации (кроме BGP-confederation в ядре, наличия BGP в некоторых стыках и самого обычного rip v2) и позволяет мониторить сети клиентов (на площадках и в офисах).
В итоге мы всегда имеем глаза, уши и, главное, руки до подопечных серверов.
Дорого ли это? На первый взгляд, закупка оборудования, прокладка и аренда каналов - это затратно. Но в условиях быстро растущего направления IT-аутсорсинга это лучшая профилактика, лекарство и прививка от ряда технических причин болезни быстрого роста. Этот технический медикамент отлично справляется со своей задачей и не дает развиться многим проблемам, которые переживали и переживают другие компании. Конечно, мы готовы платить за конкурентное преимущество, тем более, что в рабочих реалиях такое вложение окупается на коротком периоде за счет обычной экономии времени системных администраторов. Чем меньше ложных срабатываний, чем больше независимой от других факторов информации есть у специалиста, тем свободнее время, и тем лучше и больше можно делать работу позитивную, не отвлекаясь на починочно-диагностические работы.
Фактор отделенного от общедоступных сетей мониторинга так же явился своего рода социальным плюсом внутри команды - нам всем приятнее делать что-то новое и хорошее, чем диагностировать и чинить, а не отвлекаться от работы - залог спокойствия и отсутвия стрессовой обстановки.
Клиент, в свою очередь, тоже нуждается в четкой диагностике: ряду СМИ и других 24x7 сервисов требуется полное понимание происходящего с их системой, для возможной замены каких-то проблемных мест. Обычно резервный доступ к оборудованию и серверам по своей сети помогает собрать ценную для провайдера диагностику и помочь им решить проблемы их стороны. Конечно, были и случаи при размещении в провайдеро-независимых датацентрах, когда приходилось менять поставщиков каналов из-за проблемного качества, но к счастью это происходило всего несколько раз за всю практику.
Проблемы поддержки?
Как дополнительная нагрузка в плане мониторинга, как дополнительное развлечение для сетевого инженера - да. Как инженерная конструкция - нет. Ведь в сети заложено и резервирование l2 и l3, а значит с элементарной задачей она справляется легко и непринужденно.
Что дальше?
Когда будет использован разумный предел загрузки маршрутизаторов (а это будет не скоро), построим второе парралельное кольцо. Это будет независимая от первой сеть, имеющая общие точки только в подключении серверов мониторинга и хранилищ под бекапы.


Капризы WebSocket и при чём здесь костыли
Протокол WebSocket имеет свои преимущества и свои недостатки: детальный разбор

Сводная система мониторинга
Позволяет решать интеллектуальные задачи помимо задач самого мониторинга

Почему балансировщик http нужно размещать в другом сегменте
И снова о маленьких сетевых фокусах ради надежности работы web-сервисов

Стартап глазами эксплуатации и резервные штаны
Информация для осмысления

IoT Highload: особенности и подводные камни
Особенности серверных приложений, работающих с сетью IoT-устройств на практике и в теории