
Как известно, самая медленная часть в любой клиент-серверной архитектуре - это пользователь.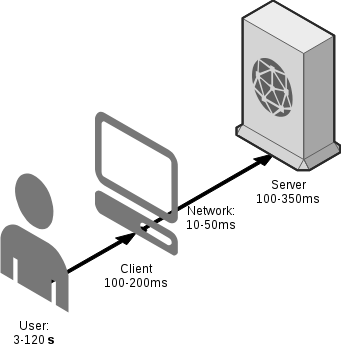 Именно он создает самые большие задержки между запросами, которые уходят к серверу, и именно он выбирает комфортную для него скорость работы с Web-приложением или сайтом. В случае "очень быстрого пользователя" и удобного интерфейса задержки между запросами могут быть чуть больше трех секунд (обычно всякие ajax-кнопочки). В случае интернет-магазина или СМИ средний интервал между переходами по страницам составляет около 2х минут. Исключением из этих правил являются перегруженные ajax-ом интерфейсы - в их случае иногда одно открытие страницы генерирует 10-20 запросов к серверу за какой-либо динамикой, но даже в этом случае 10-20 запросов это не такая и беда при переходе между страницами за 1-2 минуты.
Именно он создает самые большие задержки между запросами, которые уходят к серверу, и именно он выбирает комфортную для него скорость работы с Web-приложением или сайтом. В случае "очень быстрого пользователя" и удобного интерфейса задержки между запросами могут быть чуть больше трех секунд (обычно всякие ajax-кнопочки). В случае интернет-магазина или СМИ средний интервал между переходами по страницам составляет около 2х минут. Исключением из этих правил являются перегруженные ajax-ом интерфейсы - в их случае иногда одно открытие страницы генерирует 10-20 запросов к серверу за какой-либо динамикой, но даже в этом случае 10-20 запросов это не такая и беда при переходе между страницами за 1-2 минуты.
Серверные системы устроены из очередей и экземпляров приложения, которые эти очереди разгребают. В самом простом случае обращения к сайту, написанному на PHP и работающему в связке nginx+php-fpm без базы, есть следующие основные очереди:
- Очередь открывающихся TCP-соединений (accept) и очередь входящих пакетов уже открытых соединений (их разгребает nginx разными способами, разбирает http-протокол, реализует логику конфига и отправляет запрос по fastcgi дальше - в php-fpm)
- Такая же очередь открывающихся TCP-соединений и такая же очередь входящих пакетов, но уже в php-fpm (он разгребает ее, формирует запрос и помещает его в очередь запросов - ведь не все процессы в данный момент могут быть свободны - вероятно, придется и подождать)
- Очередь входящих запросов в php-fpm
Если ситуация осложняется базой, то в ней тоже формируются очереди на уровне TCP, очереди из запросов формируются за счет блокировок и многозадачности, очереди создаются "побочные" из-за блокировок ввода-вывода.
Очереди разгребаются рабочими процессами, работающими параллельно - это и процессы php-fpm, и процессы СУБД, и воркеры nginx. Вся суть тюнинга высоконагруженных Web-систем в том, чтобы сделать максимально быструю обработку одного запроса каждым из процессов, а также увеличивать количество параллельно работающих воркеров в узких местах.
Именно задержки между запросами создают возможность пользоваться очередями. Например, 1 воркер php-fpm в случае ответов по 50ms на страницу вполне нормально обслуживает трех одновременных пользователей: первый пользователь получает ответ сразу через 50ms, второй через 100ms, третий через 150ms. И такое время ответов для пользователей часто допустимо (конечно, при условии, что статика отдается nginx-ом быстро). Следующие три запроса эти три пользователя будут делать через 1-2 минуты, а это значит, что 1 воркер php-fpm в теории в такой ситуации может спокойно и в допустимых временных рамках обслуживать 60*3 = 90 пользователей в минуту (90, Карл!) на задержках 50-150ms. В сутки это чуть больше, чем 129 тысяч пользователей при равномерном распределении. Ввиду того, что распределение по суткам редко в каком сервисе бывает равномерным, всегда есть запас ресурса на пики нагрузки, во время которых мы имеем не 3 запроса в секунду, а 30, и имеем 10 процессов php-fpm для их обслуживания в рамках SLA 150ms на запрос максимум.
В случае IoT всё активнее
В случае IoT нет того самого пользователя, который будет ждать 1-2 минуты между запросами. Часто код на стороне устройств устроен довольно простым образом - получил ответ от первого запроса, сразу отправил второй запрос. Получил ответ от второго - отправил третий. Это нормальный кейс для большинства устройств - отправить несколько запросов в API подряд, т.к. каждый следующий запрос зависит от результата предыдущего.
Иногда разработчики оптимизируют запросы в API и вместо трех запросов отправляют один, но они просто начинают дольше работать на сервере и никакого выигрыша по времени здесь нет. Есть только выигрыш в том плане, что серверы, настроенные "под web, а не под IoT" работают чуть лучше.
Проблема с интервалом между запросами касается не только IoT, но и любых систем, которые предоставляют и используют API, но в случае IoT есть и другие веселые развлечения.
В случае IoT, в отличие от других ситуаций с API у вас может быть 10-100к клиентов, жаждущих "почти синхронности"
Главное отличие IoT от любых внутренних API - это то, что клиентов много, т.к. устройств много. Все эти клиенты имеют жестко установленные таймауты (пусть и большие) и требуют ответа от серверов в рамках допустимого SLA. Например, банкоматы требуют ответа на каждый запрос до 2х минут - это очень и очень медленно. Подходя к такому банкомату, мы часто думаем: "Какой же тормознутый банкомат". Если устройства IoT делать удобными, то нормальный SLA на взаимодействие с пользователем - до 5и секунд, а вот на автоматические запросы (отдача телеметрии и др) - уже могут быть больше.
Со стороны архитектуры IoT устройств и серверных API для них всё в целом просто: два разных API, с двумя разными точками входа и разными SLA.
Со стороны бизнес-логики серверы все-равно должны мочь обслуживать 100к человек, проснувшихся утром и пожелавших воспользоваться девайсом (большая часть IoT в современности - это мобильные устройства+приложения под них, и я всегда отношу мобильные приложения к IoT, т.к. проблемы со стороны администрирования серверов мобильных приложений и IoT-устройств, таких как сигнализации или электронные замки, одинаковы).
Со стороны администрирования: количество проданных устройств/установленных приложений не может быть равно количеству свободных процессоров в облаке чисто из экономических соображений, а значит быть и очередям, и узким местам, и всё это нужно как-то решать, дабы SLA был соблюден и время ответа устраивало пользователей даже в самых диких для админа ситуациях (например, я наблюдал такую ситуацию во время трансляций ЧМ-2018, когда половина страны за 15-20 минут попользовала API)
В случае IoT есть еще одна сложность - невозможность откатить обнову
СамоDDoS это всегда смешно, когда не грустно. Бывает, что релиз web-приложения приводит к тому, что какой-то баг в UI отправляет один за одним ajax-запросы в API. В такой ситуации всегда можно быстро откатиться и frontend-код в браузерах сменится при следующем F5.
В случае обновления большого парка устройств откатиться назад далеко не всегда возможно, а значит "какой-то глюк" может сутками DDoS-ить собственный API. Устройства нельзя банить, сервис должен работать, а SLA в это время должен быть соблюден.
Выходы из ситуаций: ускоряем ответы до максимума
Выходы из всех этих ситуаций есть, некоторые очевидны, некоторые нет. Для того, чтобы понять ситуацию получше, давайте посмотрим на схему в общем виде и поймем, где именно происходят самые большие "затыки":
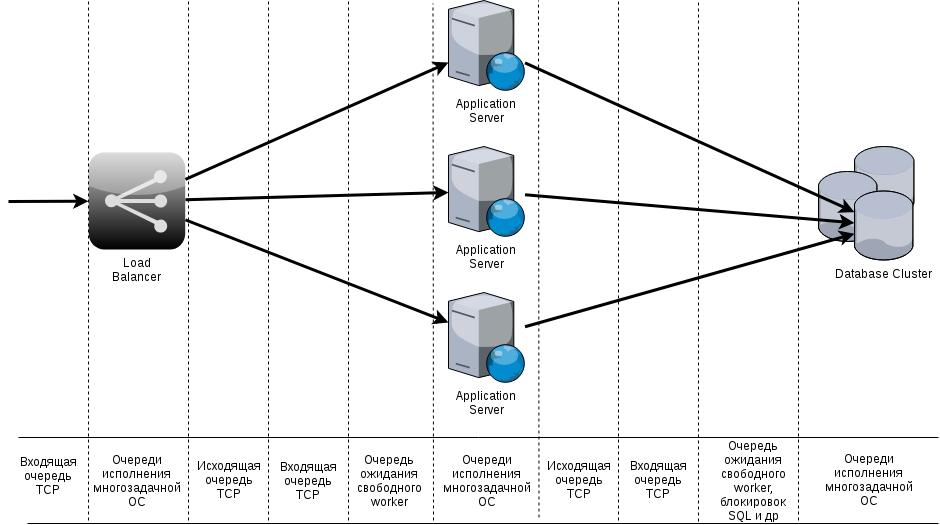
Если обратить внимание на подписи снизу, то везде, даже в процессе исполнения серверного кода, есть очереди - начиная с очередей исполнения в многозадачной ОС. Именно с помощью очередности исполнения и приоритетов вы можете на четырехъядерном CPU исполнять 200-500 процессов.
Также, если обратить внимание на схему, то в правой ее части есть база данных - крайняя точка, от скорости работы которой зависит величина минимального времени ответа Application-серверов - чем медленее база, тем больше накапливаются все очереди слева от неё.
Решение на уровне СУБД оказалось очень нетривиально - ОСРВ. А если целиком - операционные системы реального времени, либо Linux, выкрученный в его настройках в состояние, близкое к операционным системам реального времени. Это звучит очень неожиданно, особенно сейчас, в пик популярности облаков, контейнеров и кубернетесов, которые с каждым шагом своего развития добавляют новую и новую асинхронность в работе серверов. Так же неожиданно это звучит и на фоне вездесущей асинхронности в коде приложений и балансировщиков - от nodejs до nginx.
Да, асинхронность - это прекрасно. Но только тогда, когда асинхронный узел передает кому-то управление. Балансировщик запросов передает запрос дальше в Application-сервер, асинхронный балансировщик - это огромный выигрыш в ресурсах. Application Server, активно использующий СУБД, тоже лучше иметь асинхронным, ведь когда он отправляет запрос в базу - по сути он не исполняет ничего и освобожденный ресурс должен использовать кто-то.
А вот сама СУБД как конечная точка, не передающая запросов никому (кроме дисковой подсистемы), обязан отдавать ответы максимально быстро. Мы поставили эксперимент на PostgreSQL и получили потрясающий эффект от настройки RT-процессов Postgres:
- В режиме работы "1 процесс на одно ядро" можно утилизировать CPU на 100%. Это не проблема, это штатный режим работы для RT.
- Скорость ответа СУБД на идентичные запросы от идентичных баз при идентичных условиях оказалась потрясающей: 1ms на RT мультипроцессинге, и от 15ms на классической настройке систем.
- Количественная скорость обработки (запросов в секунду) в планировке, близкой к RT, стала близка к теоретически-рассчетной: порядка 950 запросов на 1 cpu со снижением расхода RAM и с четко предсказуемой потребностью в IO: такой базе даже SSD не требуется, она выполняет задачи поверх RAID6 с той же скоростью, что и на SSD. Количество IOps становится стабильным, кеши блочных устройств и FS становятся статистически стабильными.
Старая величина не давала никаких величин "запросов на cpu" и на четырехъядерном сервере с идентичными характеристиками давала не более 350 в секунду запросов не весь сервер. - Частично пропадают проблемы блокировок, т.к. база по факту становится "синхронной"
Масштабирование RT-СУБД
Масштабирование СУБД, работающей в режиме Real-Time или близкому к нему, становится очень простой задачей. Масштабировать базу данных на чтение можно инстансами с разным ресурсом внутри, в зависимости от потребностей, а это дает большую гибкость, в том числе и для экономии ресурсов.
Главные особенности такого масштабирования - это синхронная репликация и тонкая настройка балансировщика, которая не будет отправлять запрос в загруженный на 8/8 инстанс, а отправит запрос сразу в инстанс, имеющий свободный ресурс.
Вместо заключения
Проблема названа целиком, решение названо только для одной зоны - сервера баз данных. В следующей статье мы рассмотрим, как корректно настроить Application Server-ы и входящую балансировку, чтобы выдерживать и SLA на время ответов, и потенциальный DDoS от собственных устройств, и иметь возможности как экономить на ресурсе, так и бысто масштабироваться.

High Availability. Как это работает
Какие действия создадут реальную отказоустойчивость и какое бездействие создаст мину замедленного действия

Капризы WebSocket и при чём здесь костыли
Протокол WebSocket имеет свои преимущества и свои недостатки: детальный разбор

Сеть для нужд мониторинга: как устроено у нас
Не секрет, что хорошо настроенный сервер "падает" гораздо реже, чем доступ из него в Интернет

Сводная система мониторинга
Позволяет решать интеллектуальные задачи помимо задач самого мониторинга
Об архитектуре системы морского навигатора
В проекте морской навигации есть особенность, грамотная реализация которой и позволяет жить всей системе