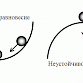
Потому что отсутствует "устойчивое равновесие"
"Устойчивое равновесие" - это механическая аналогия. С точки зрения механики, равновесие бывает двух видов: устойчивое и неустойчивое. Разница между этими равновесиями - вернется ли в исходное положение тело после оказания на него допустимого воздействия. Вот так это выглядит визуально:
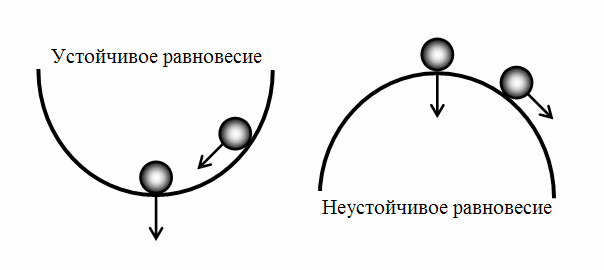
В инфраструктуре IT-проекта всё работает по абсолютно таким же инженерным принципам. Внезапно "упавший" сервис должен автоматически подняться, тормозящий базу запрос должен быть "убит", неуспешное изменение конфигурации должно вернутся назад в автоматическом режиме... Только такие меры (на уровне построения инфрастуктуры) смогут повысить uptime проекта в разы почти на ровном месте, дать людям работать в штатном режиме, спать ночами и не работать поднимателем упавших пингвинов.
Потому что мониторинг собирает не те метрики и не тем способом
Самой важной метрикой для системы, обладающей устойчивым равновесием, является ли воздействие на систему допустимым или превышает границы допустимого. Именно это и только это важно. Вы можете собирать по 6000 метрик с сервера, но не иметь совершенно никакого представления о том, какие именно метрики вам нужно наблюдать в упреждающем режиме, какие в "триггерном", а какие просто смело игнорировать.
В хорошо продуманной инфраструктуре таких метрик должно быть не более трех на один сервер. Эти метрики могут быть разными: где-то это будет Load Average + IOPS + Latency, где-то это будет Context Switches + Outbound Traffic + Interrups, где-то это будет New PID ratio + LA, где-то это будет размер занятого диска или другие метрики. В любом случае, если вам требуется собирать очень много метрик с одной машины, вы либо меряете не то, либо меряете всё. Для корректного числа метрик вас устроит любой инструмент сбора данных: zabbix, nagios и вообще всё что угодно, что может донести до дежурного специалиста информацию о состоянии машины.
Способ сбора метрик тоже крайне важен. Вообще наука о произведении замеров довольно проста, но почему-то многие игнорируют то, что они изучали на лабораторных работах в университете. Помимо способов замера, один из важных именно для IT моментов - это связь. О проведении замеров мы написали несколько статей, которые требуют отдельного внимания:
- О том как изолировать проблемы сети, проблемы мониторинга и перестать паниковать.
- О том почему один источник информации почти всегда врет
Потому что резервирование либо отсутствует, либо ухудшает ситуацию
Некорректно сделанное резервирование в большинстве случае только снижает Uptime. Причиной этому бывает целый ряд недочетов:
- "У вас был 1 падающий узел, теперь у вас два падающих узла". Довольно частая проблема, которая растет из того, что для работы резервирования требуется учесть понятие Минимальной Надежности Узла. Если ваш сервер СУБД падает раз в день и при этом восстанавливается 1 час, то смысла его резервировать практически нет, его нужно сначала делать стабильным, а потом уже делать резервы.
- "Некорректная схема". Часто при резервировании некорректно размещают балансировщики нагрузки и это приводит либо к общей точке отказа, либо к тому, что балансировщик отказывает вместе с узлом. Есть всего три варианта, как можно разместить балансировщик нагрузки, например, для подключения Application к СУБД: на сервере СУБД (плохо, ибо упадет вместе с сервером и придется ждать время, когда отработает, например, ipvs или halinux, будут оборваны соединения и возникнут прочие эфекты...), на отдельном сервере (дорого и еще и его придется резервировать), непосредственно на серверах Application (отличный подход: и экономит средства, и масштабируется до предела масштабирования Application)
- "Резервирование поверх плохой сети". Бывает еще и так: у вас отличные узлы и прекрасная схема, но вот сеть, благодаря которой резервирование и работает, может терять пакеты, падать на короткие периоды и т.п. Это неизбежно приводит к тому, что резервирование бессильно и часто при неверно выставленных временных задержках начинает "глючить".
- "Резервирование, основанное на ненадежных технологиях". Например, резервирование WEB-доступа через DNS-протокол (известно, что есть большое число клиентов, кеширующих DNS-ответы некорректно, притом начинать список можно с популярной MacOS X), или резервирование Application путем избыточности в ситуации StateFull приложения (оно просто бесполезно).
Потому что нет исправления ситуации, а есть "процесс починки"
То, что было описано выше - далеко не всё, а просто частые примеры. Причиной того, что оно вообще так работает, является человеческий и организационный фактор: никто не исправляет ситуацию, но все чинят поломки. Почему так происходит? Масса вариантов: от нехватки экспертизы, до "привычки чинить". В любом случае, любая инфрастуктура исправима. Просто нужно иметь системный подход к инфрастуктуре, не быть бессистемным администратором :-)

Сисадмины по подряду. Как с ними работать?
Быстро+Дешево+Качественно - так не бывает, в чем подвох?

Почему балансировщик http нужно размещать в другом сегменте
И снова о маленьких сетевых фокусах ради надежности работы web-сервисов
High Availability. Как это работает
Какие действия создадут реальную отказоустойчивость и какое бездействие создаст мину замедленного действия

IoT Highload: особенности и подводные камни
Особенности серверных приложений, работающих с сетью IoT-устройств на практике и в теории
Об архитектуре системы морского навигатора
В проекте морской навигации есть особенность, грамотная реализация которой и позволяет жить всей системе