
На определенном этапе, с обретением опыта в поддержке различных систем и кластеров, у нашего системного архитектора сложилось мнение об имеющихся инструментах мониторинга. Оно представляет из себя набор плюсов и минусов, которые в обобщенном виде выглядят довольно интересно. Позже эти наборы превратились в техническое задание на разработку Сводной Системы Мониторинга, выполняющей не только задачи самого мониторинга, но других задач:
- Отсечение ложных срабатываний
- Гарантия обнаружения проблем при сетевых сбоях
- Обнаружение скрытых проблем
- Возможность быстрого понимания обстановки и моментального принятия решения
Но сначала коротко о тех особенностях, которые интересны больше всего.
Проблемы классического мониторинга: способы снятия метрик
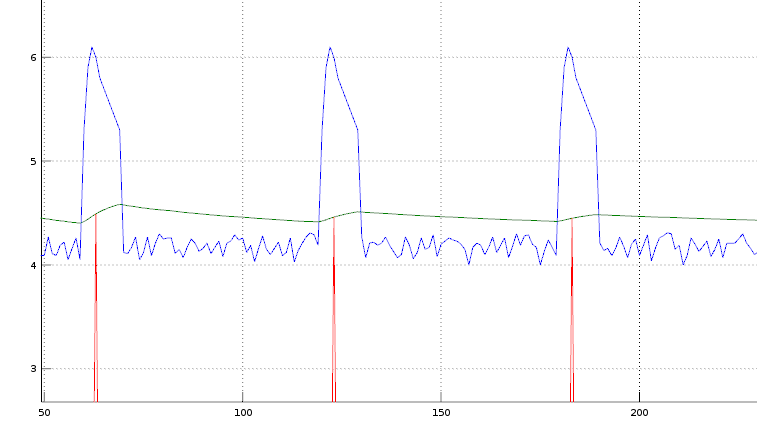 График справа отображает самую обычную ситуацию - измерение нагрузки на CPU.
График справа отображает самую обычную ситуацию - измерение нагрузки на CPU.
Синим графиком выведена утилизация процессора (в количестве 100% занятых ядер). На нем хорошо видно, что в начале каждой минуты у нас что-то запускается и потребляет на 2 ядра больше, чем в остальное время.
Зеленый график - это усредненный Load Average, на нем такие секундные пики, хоть и видны, но не так заметно, чтобы обратить на это внимание.
Красный график - это та величина, которую раз в минуту снимает, например, zabbix.
Что вы видите в итоге в zabbix и что вы в нем не видите? Видите вы среднюю нагрузку, величина которой снята раз в минуту в момент обращения. Не видите то, что раз в минуту нагрузка возрастает в полтора раза. Оно может быть и не критично, если на сервере ядер достаточно много, но, если на нем 6 ядер, то, вероятно, уже сейчас кроны работают медленнее, чем могли бы.
Давайте допустим, что ядер на сервере 6, и проблема уже имеет место быть, но вы ее не видите из-за того, что снимаете метрики по красному графику. Что это значит? Это значит что уже пошло время, когда проблема должна быть ликвидирована, но вы её не видите. Какой SLA на поддержку будет по факту, снимая информацию таким инструментом? Может быть, пожалуются клиенты и SLA будет 1-2 часа, а может быть, никто не пожалуется и проблема будет существовать месяцами, пока не усложнится какой-нибудь новой крон-задачей.
Имея некорректные замеры, невозможно не только предупредить аварию, но и среагировать на рост нагрузки в момент, когда она появилась.
Имея аггрегацию из нескольких способов замеров, всегда можно получить величины, которые будут репрезентативны и практически полезны.
Проблемы классического мониторинга: задействованные протоколы
Классически мониторинг осуществляется по протоколам ICMP, SNMP и ряду специальных протоколов, работающих поверх tcp (nrpe, протокол zabbixa и другие).
Проблема протоколов, естественно, в самих протоколах. Протоколы, работающие поверх tcp, имеют одну особенность: при малейшей проблеме в сети просто не установится соединение и мониторинг останется без информации. С одной стороны, вы сразу увидите проблему в сети, с другой стороны, Ваши метрики мониторят не сеть, а сервер, и данные должны быть получены в максимальном объеме. Отказ передавать данные по сети при неудачной установке соединения является некорректным с точки зрения логики мониторига. Зачем реагировать на сеть метрикой, с помощью который вы мониторите, работают ли сервисы внутри?
TCP-подход к мониторингу хорош гарантией доставки, но нехорош тем, что открыть соединение возможно не всегда. Например, в случае потери пакетов в районе 10% - соединения по факту не открываются. При потерях 50% выполнить "тройное рукопожатие tcp" с первого раза невозможно.
SNMP и другие протоколы, базирующиеся на UDP имеют меньше требований к сети - один пакет всегда имеет больше шансов "пролететь", чем "тройное рукопожатие tcp". UDP-пакеты можно дублировать средствами системы (iptables) и тем самым сделать избыточность в передаваемых данных. Так же их можно продублировать по разным каналам (т.к. UDP - это stateless протокол) и получить полезную информацию с бОльшей гарантией путем избыточности, чем по TCP.
Справа сравнительная таблица (просто пример) снятых метрик разными способами и сводный показатель в последней колонке:
| Metric Name |
TCP-based |
UDP-based (redundantly) | Aggregated |
| Cpu utilization | FAIL: Connection timed out | FAIL: Timed-out | NON INFORMATION |
| Eth0 Errors | FAIL: Connection timed out | FAIL: +1143 (!) | FAIL: +1143 (!) |
| Eth1 Errors | FAIL: Connection timed out | OK: 0 | OK: 0 |
| nginx service state | OK: service is UP | FAIL: Timed-out | OK: service is UP |
Как видно, по TCP мы получаем ворох Connecton timed out, а некоторые UDP проскакивают и мы видим, что внутри реально происходит: летят ошибки на интерфейсе Eth0. Сводная информация позволяет нам понять сразу, что и как происходит на машине. Полезно ли это нам? Конечно полезно - мы можем начать работать с Eth0 на стороне коммутатора уже сейчас, даже если ssh к серверу открыть не получается.
Проблемы классического мониторинга: ложные срабатывания и несрабатывания
У ложных срабатываний причинами бывает не только сеть, но и весьма более неприятные вещи:
- Баги самих систем мониторинга (в деле эксплуатации нужно быть умным и не доверять никому, в том числе авторам мониторинга)
- Проблемы в настройке конкретной системы конкретным человеком
- Периодичность сбора информации
Решение проблем
Решение проблемы довольно простое - доверять одному источнику информации нельзя. Требуется настроить несколько разных систем мониторинга, работающих на основе разных протоколов и разных методов замера. Делать это должны разные люди. Результат работы систем требуется аггрегировать по определенным правилам. Очень упрощенно эти правила выглядят так:
- Если 2 системы мониторинга изменили своё состояние, а одна нет, то эта одна врет, ее результат требуется отбросить.
- При отсутвии данных от одной из систем данные нужно брать из оставшихся систем.
- Количество систем, из которых поступают данные, должно быть простым числом, чтобы не проиходило ситуаций 50/50
- В ситуациях, когда часть систем вышла из строя и это привело к показаниям 50/50 среди оставшегося числа систем мониторинга, приоритет выбора - OK/FAIL нужно выставлять исходя из критичности величины (статическая величина, fail_adj), а так же из общей величины по конкретному серверу, исходя из величин других сервисов (fail_score). Динамическая величина позволяет в стабильной ситуации меньше реагировать на разовые потери пакетов в публичных сетях, а в ситуации нестабильности реагировать на малейшее изменение.
- Надежная сеть
Итог
Сейчас эта методика практически применяется в компании и показывает очень хорошие результаты: снижает нагрузку на дежурную службу, позволяет иметь информацию о происходящем "внутри" серверов при частично работающей сети, позволяет избежать человеческого фактора при настройке систем мониторинга.


Капризы WebSocket и при чём здесь костыли
Протокол WebSocket имеет свои преимущества и свои недостатки: детальный разбор

Сеть для нужд мониторинга: как устроено у нас
Не секрет, что хорошо настроенный сервер "падает" гораздо реже, чем доступ из него в Интернет

Почему балансировщик http нужно размещать в другом сегменте
И снова о маленьких сетевых фокусах ради надежности работы web-сервисов
Сисадмины по подряду. Как с ними работать?
Быстро+Дешево+Качественно - так не бывает, в чем подвох?
Об архитектуре системы морского навигатора
В проекте морской навигации есть особенность, грамотная реализация которой и позволяет жить всей системе