
High Availability. Как это работает
Пришел сисадмин, настроил MySQL в Galera Cluster, поднял три экземпляра приложения, сделал хранилище сессий в кластерном redis и даже сделал два балансировщика входящих запросов. Что-то затормозило, упало, сервисы легли. На вопрос "через сколько всё заработает?" нет четкого ответа и, вообще, всё это пахнет тем, что админ не знает, что произошло. Знакомая ситуация, когда формально отказоустойчивость есть, а фактически схема не работает? Вот об этом и есть эта статья.
Сперва разберем классические ошибки, которые предшествуют такому развитию событий, их немного и все они фундаментальные. Фундаментальные настолько, что для их исправления часто приходится переделывать инфрастуктуру целиком, несмотря на то, что имеющаяся схема работала годами (... пока не упала...)
Один из моментов, на котором строится работа любой кластерной системы, будь это база данных, приложение, маршрутизаторы, cdn или что угодно - это данные о состоянии каждого отдельного сервера. Эти данные нужны для принятия решений о перебалансировке нагрузки или об отключении аварийных узлов кластера.
Данные о состоянии, как и вообще сбор любых метрик и показателей - это не бинарная система "хорошо"/"плохо", "работает"/"лежит". Вникая чуть глубже в сбор данных о состоянии систем (телеметрии), открывается мир, живущий в трех состояниях: "точно работает"/"точно лежит"/"не определено".
Эти три состояния как true, false и null, и часто именно такими значениями переменных их определяют в инфрастуктурном коде. Мы пишем на Python и C, поэтому приходится немного "изгаляться", чтобы работать в логике из трех состояний, например, вводить enum-типы.
Другая сторона сбора данных: этих данных нужно избыточно много. Избыточность позволяет делать принятие решения точным и своевременным. Хороший пример на простом, поверхностном уровне:
Имеется машина, на которой работает postgresql master, рядом имеется машина postgresql secondary. В определенный момент срабатывает метрика "тормозит ввод-вывод". Вы видите, что при обычной величине iops сильно вырос latency и растет дальше. Что же делать в такой ситуации и как это делать автоматически?
Для того, чтобы было четко и ясно известно, что делать, нужно понимать, что происходит, а значит, Вам нужны не только метрики, измеряющие последствия (IO тормозит или не тормозит и подобные), но и метрики, описывающие причины таких поведений:
| vps-pgsql-1 (master, 48GB RAM) |
vps-pgsql-2 (secondary, 52GB RAM) |
|
| Остаток места | норма >20 дней запас |
норма >20 дней запас |
| Доступность СУБД | хорошо субд доступна |
хорошо субд доступна |
| Запись | хорошо запись есть |
не определено readonly secondary |
| Репликация | хорошо передает stream |
хорошо принимает stream |
| Ротация логов | хорошо логи <4GB |
хорошо логи <4GB |
| Ротация WAL | хорошо wal <30GB |
хорошо wal <30GB |
| IOWait | Проблема >5% |
хорошо <2% |
| LA | Проблема >допустимого |
хорошо допустимо |
| Slow Queries | хорошо <X |
хорошо <X |
| RAID status | хорошо raid6 функционирует |
хорошо raid6 функционирует |
| sda smart | хорошо ошибок нет, температура в норме |
хорошо ошибок нет, температура в норме |
| sdb smart | хорошо ошибок нет, температура в норме |
хорошо ошибок нет, температура в норме |
| sdc smart | хорошо ошибок нет, температура в норме |
хорошо ошибок нет, температура в норме |
| sdd smart | хорошо ошибок нет, температура в норме |
хорошо ошибок нет, температура в норме |
| dmesg errors | хорошо ошибок нет |
хорошо ошибок нет |
| RAM usage | Проблема <1GB свободной RAM |
хорошо >4GB свободной RAM |
| SWAP Usage | в норме <600MB в swap |
в норме <600MB в swap |
| SWAP IO | Проблема >50 iops |
в норме <10 iops |
Самое ценное, что есть в этих данных - простая понятная картина, с полной диагностикой, и возможность принятия решения. В такой картине четко понятно, что причиной тормозов IO является то, что активный ввод-вывод в swap (даже при небольшом объеме занятого в нем места) создает затруднения в работе системы. Причиной же активного IO в swap является то, что какие-то активно используемые страницы памяти попали в него из за нехватки RAM.
Также мы понимаем, что на secondary-сервере оперативной памяти больше, чем на primary. В этой ситуации выполнить автоматическое переключение можно и нужно - это предотвратит простой и ликвидирует уже наступившую ситуацию со снижением производительности.
Собирать точную диагностику, имеющую три состояния, реагировать автоматически и уведомлять специалистов постфактум по разрешению инцидента - одно из основных требований к современным кластерным системам.
И конечно же, это не всё. Чтобы собирать информацию, которая требуется и ничего не упустить, систему нужно не просто настроить - нужно понимать, как она устроена, спроектировать ее и на этапе проектирования определить критические точки существования системы. Если эти точки не определены - вы не сможете принять решение, какие метрики собирать, и не сможете сделать автоматическое реагирование на подобные инциденты.
Простой пример поиска критических точек в обычном (конь в вакууме) ruby-on-rails приложении, далеком от идеалов и приближенном к реальности (из повествования исключено то, что явно указывает на конкретное приложение, для соблюдения анонимности авторов кода):
Поверхностно смотрим, что вообще там работает. Nginx отправляет запросы в unicorn (web-сервер для работы ruby-приложений), ruby-приложение работает с базой PostgreSQL, а также оно работает с redis для работы с sidekiq (реализация запуска фоновых задач в ruby через очередь в redis).
Поверхностно увидеть это легко с помощью всего одной команды, запущенной на каждом из используемых серверов "netstat -anpt". Команда показывает все TCP-соединения и, разобрав вывод команды со всех серверов, можно легко построить схему кто куда ходит.
После такого осмотра мы видим критические связи приложения: для работы приложения ему должна быть доступна postgresql (из unicorn и sidekiq), доступен redis, а само приложение должно быть доступно из nginx. Вот такая визуальная схема критических связей у нас вышла:
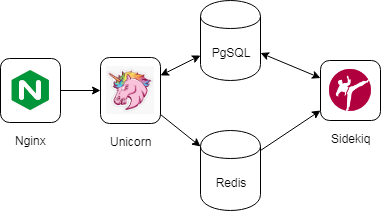
Связи называются критическими по простой причине - обрыв любой из связей приводит к немедленному прекращению работы части или всех функций приложения. Но это всего лишь поверхностный осмотр приложения. Строить на этом схему отказоустойчивости абсолютно нельзя - требуется найти все связи, а не только критические. Для этого можно например собирать сетевой трафик с серверов в течение нескольких дней (или недель - всё зависит от жизненного цикла логики приложения). Конечно, при сборе трафика стоит сразу же исключить все критические связи, т.к. они составляют 95%+ трафика, а писать информацию, которая нам и так уже известна, нет никакого смысла.
Обычно запись трафика показывает в итоге нечто вроде того, что видно на следующей схеме.
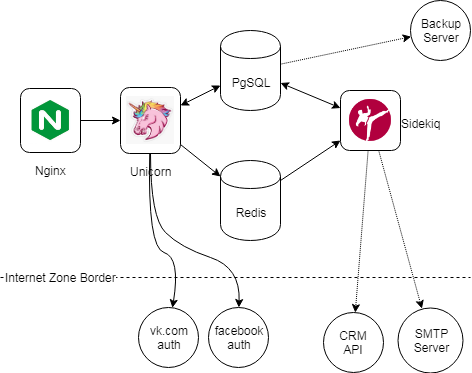
Здесь есть внешние связи разного типа: синхронные связи относятся к таким же критическим связям. Сразу нам не удалось их найти из-за того, что авторизации происходят реже, чем просмотры страниц/работа с приложением. Пополняем нашу копилку фактом "приложению необходим бесперебойный доступ в интернет (работа DNS, доступность vk.com/facebook.com, свободная полоса, работающий NAT, ...)". Это факт, о котором почему-то часто забывают на этапе реализации, и потом сталкиваются с тем, что входящие запросы в приложение приходят, а вот приложение достучаться до внешних API не может.
Есть также асинхронные связи, которые не критичны - sidekiq повторит выполнение задачи при неуспехе, а система резервного копирования снимет бекап, как только появится связь.
Критичным же для самого приложения (забыв временно о связях) является: место на локальном диске, свободная ram, CPU, работа с локальными дисками (производительность ввода-вывода), наличие свободных процессов unicorn и низкое время ожидания свободного процесса при входящем запросе. Если коротко - нужно, чтобы были свободные "воркеры", и ресурс для их деятельности.
С учетом внешних связей это почти всё, что интересно для работы приложения. Имея такие данные, можно проектировать и делать логику горячего резерва, логику автобалансировки и autoscale.
Короткое послесловие о бездействии или как проверить, что у вас всё хорошо
Проводите учения. Всегда проводите учения на отказ. Выключайте серверы, не предупреждая админа. В случайном порядке и в случайное время. Снижайте производительность дисковых подсистем (современные системы виртуализации позволяют это делать на лету), нагружайте приложение - системы должны переживать учения. Системы должы работать, когда их "шатают".
Самое вредное из всех бездействий в работе с инфраструктурой - отсутствие учений на отказ.
"Мину замедленного действия" лучше подорвать сразу, планово, и сразу исправить ситуацию, чем по прошествии многих лет, ухода из компании тройки админов, и, как итог, в срочном порядке поднимать серверы или восстанавливать данные.

Капризы WebSocket и при чём здесь костыли
Протокол WebSocket имеет свои преимущества и свои недостатки: детальный разбор

Почему балансировщик http нужно размещать в другом сегменте
И снова о маленьких сетевых фокусах ради надежности работы web-сервисов
Почему инфраструктура "лежит" и как это исправить?
Потому что отсутствует самое важное, что должно быть в любой надежной инженерной системе

Сеть для нужд мониторинга: как устроено у нас
Не секрет, что хорошо настроенный сервер "падает" гораздо реже, чем доступ из него в Интернет

IoT Highload: особенности и подводные камни
Особенности серверных приложений, работающих с сетью IoT-устройств на практике и в теории
Об архитектуре системы морского навигатора
В проекте морской навигации есть особенность, грамотная реализация которой и позволяет жить всей системе